Microsoft SkyDrive is an awesome service and the recently released
desktop synchronisation application makes keeping all of your files with
you and up-to-date a breeze.
When you first install SkyDrive it prompts you to select the folder
location in which to store your files. But what happens if you want to
change that location down the track? The application itself doesn’t
currently have that functionality (i.e. until Windows 8.1 was released!).
More on http://maxshifman.com/2012/08/move-microsoft-skydrive-folder-location-without-re-downloading-all-files/?q=2012/08/30/move-microsoft-skydrive-folder-location-without-re-downloading-all-files/
26.1.14
21.1.14

Paper Computer in Namibia
So how do we teach students how to program, if we have schools in
Namibia that do not even have electricity, never mind a computer lab or
Internet connectivity?
Easy – we create a computer that doesn’t need all that. One you can use anywhere – and which is portable and easy to use as a sheet of paper.
Based on a 30 year old concept of a “paper computer” developed by Wolfgang Back and Ulrich Rohde it consists of really nothing more than a sheet of paper that contains both the program as well as a number of data registers, and requires as additional tools only a pen or pencil (even a twig will do) and some matches that will be used to represent the contents of the data registers.

More on Edunet-Namibia
Sources:
ComputerClub 2 on WDR http://www.cczwei.de/, https://www.youtube.com/computerclubzwei
Paper Computer in PDF http://edunet-namibia.org/wp-content/uploads/delightful-downloads/2013/05/KnowHow-Computer.pdf
Easy – we create a computer that doesn’t need all that. One you can use anywhere – and which is portable and easy to use as a sheet of paper.
Based on a 30 year old concept of a “paper computer” developed by Wolfgang Back and Ulrich Rohde it consists of really nothing more than a sheet of paper that contains both the program as well as a number of data registers, and requires as additional tools only a pen or pencil (even a twig will do) and some matches that will be used to represent the contents of the data registers.
More on Edunet-Namibia
Sources:
ComputerClub 2 on WDR http://www.cczwei.de/, https://www.youtube.com/computerclubzwei
Paper Computer in PDF http://edunet-namibia.org/wp-content/uploads/delightful-downloads/2013/05/KnowHow-Computer.pdf
20.1.14
Sosyal Medyayı Anlatan Güzel bir Dizi: Black Mirror
Black Mirror sosyal medya ile ilgili bu zamana kadar yapılmış en iyi yapım. 8.7 IMDB puanına sahip olan dizinin ilk sezonu 2011 yılında çekildi. Her sezon 3 bölüm ve toplamda 6 bölüme sahip olan yapım sosyal medya, internet, mobil uygulamalar, sosyal medya ve siyaset ve sosyal medyanın geleceğini işliyor.
Kaynak: http://www.sosyalsosyal.com/sosyal-medyayi-anlatan-en-iyi-3-yapim
Kaynak: http://www.sosyalsosyal.com/sosyal-medyayi-anlatan-en-iyi-3-yapim
19.1.14
ECM Navigator
ECM Navigator ist ein Wegweiser ins Enterprise Content Management von Bitkom.
Sources:
http://www.ecm-navigator.de/
http://www.bitkom.org/Default.aspx
Sources:
http://www.ecm-navigator.de/
http://www.bitkom.org/Default.aspx
18.1.14
13.1.14
Aviation Handbooks & Manuals from FAA
FAA (Federal Aviation Administration)'s webpage for handbooks and manuals
http://www.faa.gov/regulations_policies/handbooks_manuals/aviation/
Sources:
http://www.microsoft.com/Products/Games/FSInsider/community/Pages/default.aspx,
http://www.microsoft.com/Products/Games/FSInsider/freeflight/Pages/VORtoVORNavigation.aspx
http://www.faa.gov/regulations_policies/handbooks_manuals/aviation/
Sources:
http://www.microsoft.com/Products/Games/FSInsider/community/Pages/default.aspx,
http://www.microsoft.com/Products/Games/FSInsider/freeflight/Pages/VORtoVORNavigation.aspx
10.1.14
T-SQL with Stuff
The STUFF string function inserts a string into another string. It deletes a specified length of characters in the first string at the start position and then inserts the second string into the first string at the start position.
It is very useful while generating a Comma-Separated List in a TSQL with the "XML Path" functionality.
For example, following query selects all Invoice-Numbers and the Invoice-Numbers + the status of those invoices of an order:
SELECT
ODA_SUP_ID,
ODA_SUPPLIER_NAME,
ODA_CURRENCY_CODE,
(SELECT
STUFF
(
(
SELECT ', ' + invoice_num AS [text()]
FROM DOCS
where order_num = PM_ORDER_DATA.ODA_ORDER_NO
ORDER BY invoice_num
FOR XML PATH ('')
),1,1,''
)
) as Invoice_Numbers,
(SELECT
STUFF
(
(
SELECT ', ' + invoice_num + ': ' + status_index AS [text()]
FROM P2P.dbo.DOCS
where order_num = PM_ORDER_DATA.ODA_ORDER_NO
ORDER BY invoice_num
FOR XML PATH ('')
),1,1,''
)
) as Invoice_Numbers_Status
FROM PM_ORDER_DATA
Sources:
http://technet.microsoft.com/en-us/library/ms188043.aspx
http://www.sql-server-helper.com/tips/tip-of-the-day.aspx?tkey=3934817c-1a03-4ac9-a0ba-55b2bfbaea0f&tid=72&tkey=uses-of-the-stuff-string-function
It is very useful while generating a Comma-Separated List in a TSQL with the "XML Path" functionality.
For example, following query selects all Invoice-Numbers and the Invoice-Numbers + the status of those invoices of an order:
SELECT
ODA_SUP_ID,
ODA_SUPPLIER_NAME,
ODA_CURRENCY_CODE,
(SELECT
STUFF
(
(
SELECT ', ' + invoice_num AS [text()]
FROM DOCS
where order_num = PM_ORDER_DATA.ODA_ORDER_NO
ORDER BY invoice_num
FOR XML PATH ('')
),1,1,''
)
) as Invoice_Numbers,
(SELECT
STUFF
(
(
SELECT ', ' + invoice_num + ': ' + status_index AS [text()]
FROM P2P.dbo.DOCS
where order_num = PM_ORDER_DATA.ODA_ORDER_NO
ORDER BY invoice_num
FOR XML PATH ('')
),1,1,''
)
) as Invoice_Numbers_Status
FROM PM_ORDER_DATA
Sources:
http://technet.microsoft.com/en-us/library/ms188043.aspx
http://www.sql-server-helper.com/tips/tip-of-the-day.aspx?tkey=3934817c-1a03-4ac9-a0ba-55b2bfbaea0f&tid=72&tkey=uses-of-the-stuff-string-function
8.1.14
Scale of the Universe
What does the universe look like on small scales? On large scales? The Flash animation shows this interactively.

http://cosmos.webbii.net/
http://cosmos.webbii.net/
7.1.14
Online App Studio from Microsoft
Windows Phone App Studio lets you swiftly build apps in just four steps for immediate
publishing, testing, and sharing with clients, co-workers, and focus
groups.

http://apps.windowsstore.com/
http://apps.windowsstore.com/
6.1.14
.Net Fiddle just to try code online
The website lets you just to test simple code or try out samples from other developers online.
Auto-completion, sharing and collaborating the code is also available. C# and VB.Net are available.
This tool was inspired by http://jsfiddle.net, which is just awesome.
http://dotnetfiddle.net
Auto-completion, sharing and collaborating the code is also available. C# and VB.Net are available.
This tool was inspired by http://jsfiddle.net, which is just awesome.
http://dotnetfiddle.net
Isaac Asimov's Predictions from 1964 for 2014
Isaac Asimov's predictions from 1964 for 2014 were published on New York Times on occasion of World's Fair in that year.
http://www.nytimes.com/books/97/03/23/lifetimes/asi-v-fair.html
Source: http://www.20min.ch/wissen/news/story/So-prognostizierte-Asimov-das-Jahr-2014-21762033
http://www.nytimes.com/books/97/03/23/lifetimes/asi-v-fair.html
Source: http://www.20min.ch/wissen/news/story/So-prognostizierte-Asimov-das-Jahr-2014-21762033
5.1.14
Witnessing the Real Life Apollo 13 Disaster
Witness the Real Life Apollo 13 Disaster As It Actually Happened
Source: http://gizmodo.com/witness-the-real-life-apollo-13-disaster-as-it-actually-1494377415
Source: http://gizmodo.com/witness-the-real-life-apollo-13-disaster-as-it-actually-1494377415
Elif Şafak - TED Konuşması (Türkçe Altyazılı)
Elif Şafak: Kurgunun politikası
"Hikaye dinlemek hayal gücümüzü genişletir; onları anlatmak ise kültürel duvarları aşmamızı, farklı deneyimleri kucaklamamızı, başkalarının duygularını hissetmemizi sağlar. Elif Şafak bu yalın fikirden yola çıkarak hikayelerin kimlik politiklarının üstesinden gelebileceğini anlatıyor."
"Hikaye dinlemek hayal gücümüzü genişletir; onları anlatmak ise kültürel duvarları aşmamızı, farklı deneyimleri kucaklamamızı, başkalarının duygularını hissetmemizi sağlar. Elif Şafak bu yalın fikirden yola çıkarak hikayelerin kimlik politiklarının üstesinden gelebileceğini anlatıyor."
4.1.14
Tokio in 45 Gigapixels
Krpano, a panoramic view tool developer, has published the 45 Gigapixels image of Tokio.
http://krpano.com/panos/tokyo45gp/
http://www.360cities.net/
http://krpano.com/panos/tokyo45gp/
http://www.360cities.net/
1.1.14
A very generic Regular Expression Date pattern
This generic Regular Expression Date pattern covers also leap years for European formats (dd.mm.yyyy):
GENERIC_DATE_PATTERN = "^((((0?[1-9]|[12]\d|3[01])\.(0?[13578]|1[02])\.((1[6-9]|[2-9]\d)?\d{2}))|((0?[1-9]|[12]\d|30)\.(0?[13456789]|1[012])\.((1[6-9]|[2-9]\d)?\d{2}))|((0?[1-9]|1\d|2[0-8])\.0?2\.((1[6-9]|[2-9]\d)?\d{2}))|(29\.0?2\.((1[6-9]|[2-9]\d)?(0[48]|[2468][048]|[13579][26])|((16|[2468][048]|[3579][26])00)|00)))|(((0[1-9]|[12]\d|3[01])(0[13578]|1[02])((1[6-9]|[2-9]\d)?\d{2}))|((0[1-9]|[12]\d|30)(0[13456789]|1[012])((1[6-9]|[2-9]\d)?\d{2}))|((0[1-9]|1\d|2[0-8])02((1[6-9]|[2-9]\d)?\d{2}))|(2902((1[6-9]|[2-9]\d)?(0[48]|[2468][048]|[13579][26])|((16|[2468][048]|[3579][26])00)|00))))$"
More info on Regular Expressions:
GENERIC_DATE_PATTERN = "^((((0?[1-9]|[12]\d|3[01])\.(0?[13578]|1[02])\.((1[6-9]|[2-9]\d)?\d{2}))|((0?[1-9]|[12]\d|30)\.(0?[13456789]|1[012])\.((1[6-9]|[2-9]\d)?\d{2}))|((0?[1-9]|1\d|2[0-8])\.0?2\.((1[6-9]|[2-9]\d)?\d{2}))|(29\.0?2\.((1[6-9]|[2-9]\d)?(0[48]|[2468][048]|[13579][26])|((16|[2468][048]|[3579][26])00)|00)))|(((0[1-9]|[12]\d|3[01])(0[13578]|1[02])((1[6-9]|[2-9]\d)?\d{2}))|((0[1-9]|[12]\d|30)(0[13456789]|1[012])((1[6-9]|[2-9]\d)?\d{2}))|((0[1-9]|1\d|2[0-8])02((1[6-9]|[2-9]\d)?\d{2}))|(2902((1[6-9]|[2-9]\d)?(0[48]|[2468][048]|[13579][26])|((16|[2468][048]|[3579][26])00)|00))))$"
More info on Regular Expressions:
- http://www.codeproject.com/Articles/9099/The-30-Minute-Regex-Tutorial
- http://blogs.msdn.com/b/zainnab/archive/2008/03/11/regular-expression-webcast-series.aspx
- Regular Expression Language - Quick Reference
- Mastering Regular Expressions, by Jeffrey Friedl, Chapter 9, .NET is available on-line for free
Ephesoft Guide to Forms Processing Terms
Ephesoft Advanced Capture solutions provide significant benefits to
improving the paper process within organizations. The purpose of this
document is to provide a high level overview of the capabilities of
Ephesoft and the terminology used with this technology.
Forms Processing - Refers to the capture of information from documents through an automated process. Documents enter organizations and have little or no value until they are identified as to what they are and what metadata is on them. Forms processing refers to the automation of scanning, reading and interpreting the information on the documents to help automate workflows and add value to an organization.
Scanning - Usually the first process of forms processing where paper documents are converted to images that can be read by the computer and routed electronically. Scanning can be done by slow speed and high speed scanners depending on the user's needs. For the best Optical Character Recognition,it is recommended that scanning is done at 300 dots per inch to provide the optimal image for good recognition.
PDF/PDF Plus Text - Refers to a standard format of an image file once scanned. PDF stands for Portable Document Format which is a document image standard created by Adobe Systems. A PDF Plus Text document contains an image of a document plus the associated text data which can be used for search and retrieval functions in order to locate the document or information on the document at a later date.
Tiff-Tagged Image File Format - Refers to a file type which is an electronic image (or Picture) of a document. A tiff image can be used to route and store pictures of documents within a computer system. Many manual file cabinets are converted to electronic format through the conversion of documents to electronic tiff files.
OCR - Optical Character Recognition - This term is used to represent the capability of computers to read and interpret machine printed characters on documents. For clean documents,expectations can be about 95 out of 100 characters that can be read correctly without human intervention. This number can be higher or lower depending on the quality of the original documents.
ICR-Intelligent Character Recognition-Similar term to OCR, but relates to hand printed information. In general, this technology works well only with forms designed for recognizing handprint which include structured boxes and drop out form colors.
BCR-Bar Code Recognition-The ability to read and interpret the data from bar codes printed on paper documents.Several bar code types exist including Code39, CODABAR,Interleaved 2 of 5,Code93 and more.
OMR - Optical Mark Recognition - The ability to read boxes or circles with tics on them as in a
survey or questionnaire. The system looks for fill or no fill within the box to determine whether it is checked or not.
Batch - A group of one or more documents processed at a time within the system.
Advanced Forms Processing - Generally refers to technologies of reading documents beyondsimply reading a bar code or producing a PDF output file. These generally include free form(unstructured) data extraction and full page document classification.
Fixed Forms Processing -Refers to initial forms processing technology that would use a fixed forms template to OCR and extract meta data from a document. The forms have to be the same and identified and the data has to be in the EXACT same location on each document for this technology to work. This technology has been replaced with unstructured extraction since it is much more efficient. Some rare cases still exist to utilize fixed forms extraction.
Document Classification - The process whereby different document types are defined in order to be used for later processing.
Document Separation -The process of determining the total number of pages within each document type and separating all the pages of one document type from another document type. This is also the same as determining where one document ends and the next one begins in a stream of images.
Image Classification - This technology is used to identify and separate document types in a stream of scanned pages. The technology uses finger print matching or matching of similar patterns of a particular form. It works well for standard pre defined forms, but does not work for textual types of documents of information since there are no form attributes on those to match to.
Full Page Text Classification - This technology is used to identify and separate document types in a stream of scanned pages. It can distinguish between each document type to classify the documents and can also separate each document type even if they have variable pages. It does this by reading the full page of each document's text and understands similarities between pages and documents much like a human would. Documents can usually be trained by providing samples. The advantage of this technology is that bar code separator pages and barcode page identifiers are not needed to separate and classify documents.
Document Review-This is a process where the user is asked to review the classification results from the system. It is an exception process designed to review only those documents that the system did not have enough confidence to determine the proper document type. The operator is show only the exceptions and has the option to agree with the choice or select another outcome. This process is significantly faster than performing the classification in an entirely manual process.
Metadata - Refers to the information that is associated with the document images.Examples of metadata that can be associated with an image are document type, field names and data elements. For example an image could be identified as an invoice and some metadata fields could in Invoice Date, Invoice Number, Total Amount, etc. The metadata would then be used to populate another system so that it can be used to automate a process.
Extraction - General term referring to the reading of data on a document image and pulling the data off to be used in another process. For example, an invoice image may have the fields of date, invoice number and total amount "extracted" and transferred to an other system where it can be used to post the invoice information or used to retrieve the invoice image later on if needed.
Free Form (unstructured) Data Extraction - Refers to the ability of a computer device to read a full page document of text and selectively extract data elements based on characteristics and formats of data surrounding it. For example, look anywhere on the page for the word "invoice"and when you find that specific word, look to the right of it and pull of an 8 digit number and populate my database with it. These can be as simple or complex as needed to extract information off of documents. The advantage of this technology is that the exact document type does not need to be known ahead of time as the system is just looking for variable data on any page.
Document Validation - In this process, metadata that was automatically extracted from the document is manually reviewed by the operator. Data that was not read with confidence or that did not satisfy a table or field validation is presented to the operator to correct. This is an exception process only and is much quicker than entering the data in an entirely manual process.
Confidence Threshold - The setting to determine at what point an operator should review the results created by the automated computer system. For example, if a confidence level of 70% was set, the computer would pass all results that it was less than 70% confident on to the user to validate. This is an adjustable parameter which is used to fine tune the system and maximize throughput while reducing errors.
Release - Generally refers to the end result process of a forms processing system. Forms processing systems take in images and release images and data. The data that is released from the system can connect to data base, workflow engines and other back end systems. A release procedure is the formal process which takes the data and images from the forms processing system and places it into the repository or system that needs to store or act on the data.
Source:
http://www.ephesoft.com/aboutus/ephesoft-blog/380-ephesoft-guide-to-forms-processing-terms
http://www.ephesoft.com/aboutus/ephesoft-blog
Terminology
Forms Processing - Refers to the capture of information from documents through an automated process. Documents enter organizations and have little or no value until they are identified as to what they are and what metadata is on them. Forms processing refers to the automation of scanning, reading and interpreting the information on the documents to help automate workflows and add value to an organization.
Scanning - Usually the first process of forms processing where paper documents are converted to images that can be read by the computer and routed electronically. Scanning can be done by slow speed and high speed scanners depending on the user's needs. For the best Optical Character Recognition,it is recommended that scanning is done at 300 dots per inch to provide the optimal image for good recognition.
PDF/PDF Plus Text - Refers to a standard format of an image file once scanned. PDF stands for Portable Document Format which is a document image standard created by Adobe Systems. A PDF Plus Text document contains an image of a document plus the associated text data which can be used for search and retrieval functions in order to locate the document or information on the document at a later date.
Tiff-Tagged Image File Format - Refers to a file type which is an electronic image (or Picture) of a document. A tiff image can be used to route and store pictures of documents within a computer system. Many manual file cabinets are converted to electronic format through the conversion of documents to electronic tiff files.
OCR - Optical Character Recognition - This term is used to represent the capability of computers to read and interpret machine printed characters on documents. For clean documents,expectations can be about 95 out of 100 characters that can be read correctly without human intervention. This number can be higher or lower depending on the quality of the original documents.
ICR-Intelligent Character Recognition-Similar term to OCR, but relates to hand printed information. In general, this technology works well only with forms designed for recognizing handprint which include structured boxes and drop out form colors.
BCR-Bar Code Recognition-The ability to read and interpret the data from bar codes printed on paper documents.Several bar code types exist including Code39, CODABAR,Interleaved 2 of 5,Code93 and more.
OMR - Optical Mark Recognition - The ability to read boxes or circles with tics on them as in a
survey or questionnaire. The system looks for fill or no fill within the box to determine whether it is checked or not.
Batch - A group of one or more documents processed at a time within the system.
Advanced Forms Processing - Generally refers to technologies of reading documents beyondsimply reading a bar code or producing a PDF output file. These generally include free form(unstructured) data extraction and full page document classification.
Fixed Forms Processing -Refers to initial forms processing technology that would use a fixed forms template to OCR and extract meta data from a document. The forms have to be the same and identified and the data has to be in the EXACT same location on each document for this technology to work. This technology has been replaced with unstructured extraction since it is much more efficient. Some rare cases still exist to utilize fixed forms extraction.
Document Classification - The process whereby different document types are defined in order to be used for later processing.
Document Separation -The process of determining the total number of pages within each document type and separating all the pages of one document type from another document type. This is also the same as determining where one document ends and the next one begins in a stream of images.
Image Classification - This technology is used to identify and separate document types in a stream of scanned pages. The technology uses finger print matching or matching of similar patterns of a particular form. It works well for standard pre defined forms, but does not work for textual types of documents of information since there are no form attributes on those to match to.
Full Page Text Classification - This technology is used to identify and separate document types in a stream of scanned pages. It can distinguish between each document type to classify the documents and can also separate each document type even if they have variable pages. It does this by reading the full page of each document's text and understands similarities between pages and documents much like a human would. Documents can usually be trained by providing samples. The advantage of this technology is that bar code separator pages and barcode page identifiers are not needed to separate and classify documents.
Document Review-This is a process where the user is asked to review the classification results from the system. It is an exception process designed to review only those documents that the system did not have enough confidence to determine the proper document type. The operator is show only the exceptions and has the option to agree with the choice or select another outcome. This process is significantly faster than performing the classification in an entirely manual process.
Metadata - Refers to the information that is associated with the document images.Examples of metadata that can be associated with an image are document type, field names and data elements. For example an image could be identified as an invoice and some metadata fields could in Invoice Date, Invoice Number, Total Amount, etc. The metadata would then be used to populate another system so that it can be used to automate a process.
Extraction - General term referring to the reading of data on a document image and pulling the data off to be used in another process. For example, an invoice image may have the fields of date, invoice number and total amount "extracted" and transferred to an other system where it can be used to post the invoice information or used to retrieve the invoice image later on if needed.
Free Form (unstructured) Data Extraction - Refers to the ability of a computer device to read a full page document of text and selectively extract data elements based on characteristics and formats of data surrounding it. For example, look anywhere on the page for the word "invoice"and when you find that specific word, look to the right of it and pull of an 8 digit number and populate my database with it. These can be as simple or complex as needed to extract information off of documents. The advantage of this technology is that the exact document type does not need to be known ahead of time as the system is just looking for variable data on any page.
Document Validation - In this process, metadata that was automatically extracted from the document is manually reviewed by the operator. Data that was not read with confidence or that did not satisfy a table or field validation is presented to the operator to correct. This is an exception process only and is much quicker than entering the data in an entirely manual process.
Confidence Threshold - The setting to determine at what point an operator should review the results created by the automated computer system. For example, if a confidence level of 70% was set, the computer would pass all results that it was less than 70% confident on to the user to validate. This is an adjustable parameter which is used to fine tune the system and maximize throughput while reducing errors.
Release - Generally refers to the end result process of a forms processing system. Forms processing systems take in images and release images and data. The data that is released from the system can connect to data base, workflow engines and other back end systems. A release procedure is the formal process which takes the data and images from the forms processing system and places it into the repository or system that needs to store or act on the data.
Source:
http://www.ephesoft.com/aboutus/ephesoft-blog/380-ephesoft-guide-to-forms-processing-terms
http://www.ephesoft.com/aboutus/ephesoft-blog
Google Code with Tortoise SVN
Here's how to import your project using TortoiseSVN, the most popular Windows SVN client.
I assume you have created your Google Code (GC) project and it is called PROJECT and that the local source you want import is in a directory tree rooted at SOURCE.
a) Go to your GC home page and select the "Profile" menu - this will give you your UID and then click the "Settings" tab to find your PASSWORD - this is not the same as your gmail password.
b) In Windows explorer, right click on your SOURCE directory to get the Tortoise context menu and choose "Import..."
This will pop up a dialog asking for the repository url. Enter the following:
https://PROJECT.googlecode.com/svn/trunk
c) You will be prompted for a userid & password - enter UID and PASSWORD as described above.
Your project should now be uploaded to the GC repository. From now on you can use the Tortoise repo-browser and other tools to access it via the url above.
For more information: http://code.google.com/p/support/wiki/GettingStarted
I assume you have created your Google Code (GC) project and it is called PROJECT and that the local source you want import is in a directory tree rooted at SOURCE.
a) Go to your GC home page and select the "Profile" menu - this will give you your UID and then click the "Settings" tab to find your PASSWORD - this is not the same as your gmail password.
b) In Windows explorer, right click on your SOURCE directory to get the Tortoise context menu and choose "Import..."
This will pop up a dialog asking for the repository url. Enter the following:
https://PROJECT.googlecode.com/svn/trunk
c) You will be prompted for a userid & password - enter UID and PASSWORD as described above.
Your project should now be uploaded to the GC repository. From now on you can use the Tortoise repo-browser and other tools to access it via the url above.
For more information: http://code.google.com/p/support/wiki/GettingStarted
What happened to the Immediate window in my Visual Studio 2010 IDE?
So you lost your Immediate window in Visual Studio and you want it back, well here are the ways you can get it back:





Done.
Source: http://blogs.msdn.com/b/devschool/archive/2011/07/22/what-happened-to-the-immediate-window-in-my-visual-studio-2010-ide.aspx
- In the command window type immed and then enter.
- Select Tools-Customize (that’s Tools, not View)

- Select the command tab and then scroll down to the View-Other Windows selection, this is where you will place the Immediate window selection:

- Click the Add Command button and then select Debug in the categories and Immediate in the selection list box Commands, then select OK:

- You may need to move the Immediate command up or down, I like mine under the “View-Other Windows” menu item.

- Once you get everything set, you should see the following!

Done.
Source: http://blogs.msdn.com/b/devschool/archive/2011/07/22/what-happened-to-the-immediate-window-in-my-visual-studio-2010-ide.aspx
Beyin Kanaması Nasıl Anlaşılır
Beyin
kanaması olduğunu anlamak için aşağıdaki dört adımı uygulamak gerekebilir. Beyin kanaması semptomlarını anlamak cok zor olabilir. Fakat bu konuda
bilgisiz olup beyin kanaması geçiren kişiye müdahale edilmezse, beyni
çok ciddi zararlar görebilir. Doktorlar, artık herkesin aşağıdaki 4
adımı uygulamakla bunu kolayca anlayabileceğini söylemektedir.
1. Kişinin gülümsemesini istemek (eğer yapamazsa = Felç demektir)
2. Kişinin çok basit bir cümle söylemesini istemek (“Bu gün çok güzel bir gün”) gibi.
3. Kişiden her iki kolunu birden kaldırmasını istemek.
4. Kişiden dilini dışarı çıkartmasını istemek. Eğer yamulmuşsa bu da felç geçirdiğine işarettir.
Eğer kişi bu dört adımdan birini yerine getiremiyorsa – “lütfen” derhal acil
servise haber veriniz ve doktora telefonda durumu izah ediniz.
1. Kişinin gülümsemesini istemek (eğer yapamazsa = Felç demektir)
2. Kişinin çok basit bir cümle söylemesini istemek (“Bu gün çok güzel bir gün”) gibi.
3. Kişiden her iki kolunu birden kaldırmasını istemek.
4. Kişiden dilini dışarı çıkartmasını istemek. Eğer yamulmuşsa bu da felç geçirdiğine işarettir.
Eğer kişi bu dört adımdan birini yerine getiremiyorsa – “lütfen” derhal acil
servise haber veriniz ve doktora telefonda durumu izah ediniz.
Subscribe to:
Comments (Atom)
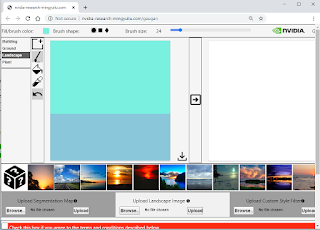
Nvidia's GauGan App
NVIDIA's GauGAN AI Machine Learning Tool creates photorealistic images from Simple Hand Doodling http://nvidia-research-mingyuliu.com/...
-
 In einem Blog auf ZDNet.com werden die aktuellen technologischen Trends sehr gut dargestellt. http://www.zdnet.com/article/the-enterpri...
In einem Blog auf ZDNet.com werden die aktuellen technologischen Trends sehr gut dargestellt. http://www.zdnet.com/article/the-enterpri... -
Code Snippet Index Page (from KTM Wiki) A Access DPI Access an External Database Active Page Index Add a Word Add an Alternative ...
-
 Here are two links with Microsoft's free Ebook links: Largest FREE Microsoft eBook Giveaway: Microsoft eBooks from Eric Ligman (Micros...
Here are two links with Microsoft's free Ebook links: Largest FREE Microsoft eBook Giveaway: Microsoft eBooks from Eric Ligman (Micros...